Getting started with RDF in Prolog
Recently I got involved in a web project that uses RDF as a backend. The application code is written in Prolog and runs on SWI-Prolog. SWI-Prolog comes with an implementation of RDF storage engine. We use the implementation as a database.
RDF
RDF stands for Resource Description Framework. The name is very broad and generic and does not say anything about its applicability. For a newcomer, it's really hard to wrap your head around it. Most articles treat RDF strongly together with other technologies that were intended to be the underlying building blocks of the Semantic Web. There are so many technologies, frameworks and concepts around the Semantic Web that even listing them would take lots of pages and make your head hurt.
Triples
RDF data model uses triples. That's why RDF storage engines are also called
triplestores. Triples are in the form of (Subject, Predicate, Object). This
form is comparable to the Entity-Attribute-Value pattern.
Both subject and predicate (or all three) are represented using
IRIs. IRI is similar to an URI but can also contain Unicode
characters. URL/IRI prefixes are used in most practical applications and actual file formats to cut down verbosity and make data representation more
compact. The prefixes work like XML namespaces. The URL/IRI approach helps to avoid name clashes between supposely-different entities in different
applications and datasets.
Why triples?
Triples make it trivial to encode data inside directed graphs (mathematical objects). Many relationships can be expressed as graphs.
RDF:

Directed graph:
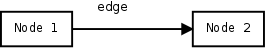
RDF objects can be IRIs (referring to other subjects) or simple values (literals) such as numbers and strings. A bigger example of a system of users and drawings:
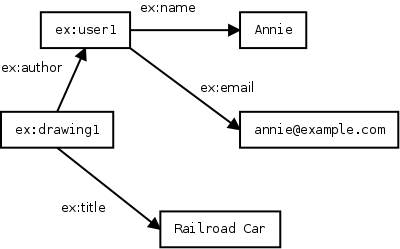
Annie, annie@example.com and Railroad Car are literal values. name, email,
title and author are predicates, prefixed by the ex prefix (this could stand for
http://example.com/). user1 and drawing1 are resources. Generic UUIDs instead of identifiers like
user1 and drawing1 can be used.
Storing and sharing triples
As mentioned above, there are special-built triple storages and SWI-Prolog contains one. There are also standardised serialization formats. The formats are useful for sharing data between different applications. The serialization format does not matter when the triples are not shared but only stored.
XML
The standardized RDF/XML format is very verbose and generally unsuitable for editing manually. But well, XML has to be tried to be used for everything.
Turtle
The Turtle format is suitable for manually editing triple information. The name stands for Terse RDF Triple Language.
The example with the user and the drawing:
@prefix ex: <http://example.org/ns#>
<ex:user1>
ex:name "Annie"
ex:email "annie@example.com"
<ex:drawing1>
ex:title "Railroad Car"
ex:author <ex:user1>
Turtle is supported by SWI-Prolog and we use it for loading some externally-generated data.
Embedding
In web aplications, triples can be shared by embedding them into HTML. This is how Facebook's Open Graph protocol works and how product data (using the GoodRelations vocabulary) from the web shops is extracted by Google and by other search engines.
Querying triples
In Prolog it's very natural to query triples directly using the rdf/3
predicate (a Prolog predicate has nothing to do with an RDF predicate). When one
or more arguments are given as unbound variables, all matching solutions would be retrieved by successive backtracking. This makes it easy to build
a "query" by joining multiple rdf calls.
Example: finding drawing author' name:
drawing_author_name(Drawing, Name):-
rdf(Drawing, ex:author, Author),
rdf(Author, ex:name, Name).
Query languages
There are many standardized RDF query languages. SWI-Prolog supports SPARQL and SeRQL. I have briefly checked out SPARQL but have not found it very useful in Prolog where the direct query mechanism exists. I can see that a separate query language could be useful in a more traditional programming language that has no backtracking.
Layers on top of RDF
Other technologies closely surround RDF to make it more useful for the Sematic Web and possibly other purposes. Many of them are based on some logics (albeit with different rules). The most widely mentioned ones are RDFS and OWL.
RDFS
RDFS stands for RDF Schema. It adds a number of standardized predicates to describe entities and relations between. The set of standardized predicates enables entailment. Entailment is a process of deducing new triples from existing using the rules embedded inside an RDFS engine. The entailment comes with limited expressiveness and we have not found much use for it.
SWI-Prolog contains some support for RDFS and has additional support in the plRdf pack.
OWL
OWL (Web Ontology Language) is a set of languages. They are similar to RDFS but much more powerful and they come with an Open World Assumption (queries can get clear answer "unknown"). A schema/model described in an OWL language is called an ontology. I'm not very familiar with this and we use help from an expert when we deal with it.
Further reading
I strongly recommend the book Semantic Web for The Working Ontologist. The material is a subset of what you would find by going through online guides, standards, Wikipedia pages or scientific articles that all assume you already know lots about it. Another good source is SWI-Prolog manual for Semantic Web library.